
Performance Testing can be daunting for many software testers, right from a novice to well trained and experienced professionals. Not knowing the intricacies of performance testing can render the performance test results inaccurate and useless. Ticking Minds has been at the forefront of performance testing for many years now & we have outlined a few pointers to keep you well informed in the performance testing space.
- Invest on Performance early in the Life-cycle
- Performance Improvement for Inflight Projects
- Performance Improvement for New Projects
- Bottleneck Identification Approach
- Tiny Misses in Performance Test that can Hugely Cost Enterprises
Performance testing is not a single entity but an umbrella term which encompasses Load Testing, Spike Testing, Volume Testing, Stress Testing, Soak Testing, Endurance Testing etc. It is a non-functional aspect of application/web testing which focuses solely on how an app/web functions under extreme load/stress. Performance testing determines the app/web remains stable, retains loading speed, is responsive & scalable even while experiencing an unprecedented load.
Invest on performance early in the life cycle

Often performance test gets about 3-to-4-week allocation at the maximum, and that too just before going live and after functional readiness clearance. This positions the entire human ecosystem (clients, business stakeholders, project managers, technical architects, release managers, performance assessment teams) under undue duress. Everyone is looking for quick wins in application performance assessment in the shortest possible time window. This leaves you with very little time window to course correct, as we are already into deep waters. This is not a very practical and efficient situation to be in.
We strongly recommend that project management team budgets for the resources, time, and money to carry out performance assessments early in the project life cycle. Unearthing performance issues early in life cycle provides great value as a proactive & preventive analysis rather than late in the project life cycle hindsight analysis.
Needless to say, a functionally rich product with poor performance is dead on arrival. So, validating the product performance at the earliest possible stage is absolutely necessary.
Performance improvement – inflight projects

These are systems that are already live in production and likely to have performance issues. In this case, following a structured approach as mentioned below would be useful.
- Ideally, start off the collaboration hearing the feedback from client/business/client facing teams. Understand from them what are the expectations in terms of performance response times/business operation completion times.
- Document the production and pre-prod instances hardware sizing, deployment models, architectural model, configurations settings explicitly.
- Analyse the production meta-data and understand the most frequently used workflows in the application. Most importantly Cross-validate this information with the technical teams, calibrate if needed, based on their advice.
- Collate information from monitoring teams, infrastructure teams with respect to their observations on resource utilization, analyse logs to seek insights on which layer is the bottleneck. If information available is inconclusive, then seek the help of the implementation team to add instrumentation to the layers to get layer wise measurements.
- Understand the various business operations carried out by the user, understand usage patterns of users, workload arrival rates and then devise a peak load workload mix that will be realistic simulation of real-life behaviour. Most importantly validate the workload model using performance engineering laws to check for the total transactions to be simulated with a particular load arrival rate.
Document all findings mentioned above, get a sign off from the relevant stake holders before moving on to the next step. Getting the buy-in from different stakeholders is very critical, as a part of the collaboration exercise, one should not be in a situation where the basic premise of collaboration does not get questioned at later stage. - Having collated the various workflows/business operations carried out by the user, carryout these operations manually, then measure the response times manually using the developer tools of the browser. Next, look to simulate those behaviours using any one performance simulation tool like JMeter, NeoLoad, LoadRunner. In addition to simulating the workflows, understand the various data needs for those business operations and have those operations use such realistic data.
- Begin off with 2-3 iterations of single user tests for each isolated workflow to build some baseline numbers. Compare these performance measurements against manual operations to check and see if the simulation is in line with the manual operations.
- Next, see if these response time measurements for a single user are in line with the customer expectations. If these are in line with the customer expectations, then increase the number of concurrent users for that workflow and build a baseline number carrying out the test for 30 minutes. Continue the isolated measurements for other workflows as well.
- From the above operation of increased concurrency, if there is a performance degradation observed, then flag those issues, assess if it is an infrastructure limitation or true application performance issue. If the initial analysis is an application performance issue, then try to nail down the performance issue from a design perspective as originating from which particular layer. On a need basis enable /design additional instrumentation with the help of the project team.
- Once all workflows are simulated for single user, increased concurrency and no performance issues are still open, then move on the workload model-based test execution across all transactions with single user for each of the workflows in the model. Get baseline measurements again from this workload model, compare the performance against the individual baseline measurement obtained earlier. If results are in line with expectations, then proceed against peak workload model.
- Ensure that there are enough realistic data volumes created for large volume peak workload mix tests. It is important to note and simulate the load from outside the network (as necessary in the context of the application nature). Peak workload mix tests are then executed for the desired duration, ideally 90 minutes with 20 minutes of ramp up, 60 minutes of hold time and 10 minutes of ramp down.
- From a client-side perspective, look at the 90% response times of all transaction operations carried out. Mark response times that are greater than expected response time SLAs defined. Compare those transactions that had higher response times with the single user workload mix test as well with the isolated baseline measurements.
- Analyse as to why the peak workload mix test had higher response times – was it a pure performance issue due to design or more of hardware limitation.
- Collaborate jointly with the infrastructure and monitoring team during the performance tests to nail down performance bottlenecks together. Access application logs during the test run to see if that can provide additional insights on the performance bottleneck. Jointly conclude the root cause of performance issue, look for ways to address the issue and retest once the performance issue fix is provided. Certify/Sign off only after the performance issue no longer occurs.
- It is important to note that any infrastructure limitation can be unearthed from load test or stress test or endurance test depending upon on the nature of problems being observed.
Performance improvement – new projects

It is always a privilege to be early in performance assessment in new projects. These are systems that are being designed and have a potential 5-6 month go live timeline. In this case, let us follow the steps mentioned below.
- Ideally, start off the collaboration with the client/business/client facing teams. Understand from them what are the expectations in terms of performance response times/business operation completion times. This could be a scenario where the sizing might have been type casted and refinements/validated.
- If it is a scenario where single box deployments are being tried in the initial phase of the project, understand and document the production and pre-prod instances hardware sizing, deployment model, architectural model, configurations settings explicitly. Cross-validate this information with the technical teams, calibrate, if needed, based on their advice.
- During the initial phase of the project only certain basic features might be designed and implemented. Talk to the business operations team and understand the business operations that are being built currently by the user, understand usage patterns of users, workload arrival rates and then understand the number of users.
Document all findings mentioned above, get a sign off from the relevant stake holders before moving on to the following steps. Getting the buy-in from different stakeholders is very critical, as a part of the collaboration exercise, one should not be in a situation where the basic premise of collaboration does not get questioned at later stage. - For the given workflows, carryout these operations manually, then measure the response times manually using the developer tools of the browser.
- Try to simulate those behaviours using any one performance simulation tool like JMeter, NeoLoad, LoadRunner. In addition to simulating the workflows, understand the various data needs for those business operations and have those operations use such realistic data.
- Begin off with 2-3 iterations of single user tests for existing isolated workflow to build some baseline numbers. Compare these performance measurements against manual operations to check and see if the simulation is in line with the manual operations.
- Next, see if this response time measurement for a single user are in line with the customer expectations. If these are in line with the customer expectations, then increase the number of concurrent users for that workflow and build a baseline number carrying out the test for 30 minutes. Continue the isolated measurements for other built workflows as well.
- From the above operation of increased concurrency, if there are performance degrades observed then flag those issues, assess if it is an infrastructure limitation or true application performance issue. If the initial analysis is an application performance issue, then try to nail down the performance issue from a design perspective as originating from which particular layer. On a need basis enable /design additional instrumentation with the help of the project team.
- Once all workflows are simulated for single user, increased concurrency and no performance issues are still open, then move on the workload model-based test execution across all transaction with single user for the available transactions as per the workload mix text. Get baseline measurements again from this workload model, compare the performance against the individual baseline measurement obtained earlier.
- From a client perspective, look at the 90% response times of all transaction operations carried out. Mark response times that are greater than expected response time SLAs defined. Compare those transactions that had higher response times with the single user workload mix test as well with the isolated baseline measurements. Analyse as to why the peak workload mix test had higher response times – was it a pure performance issue due to design or more of hardware limitation.
- Collaborate with the infrastructure and monitoring team during the performance tests to nail down performance bottlenecks together. Access application logs during the test run to see if that can provide additional insights on the performance bottleneck. Jointly conclude the root cause of performance issue, look for addressing the issue and retest once the performance issue fix is provided. Certify/Sign off only after the performance issue no longer happens.
- Incrementally add newer functions to the tests to get performance measurements.
Bottleneck identification approach
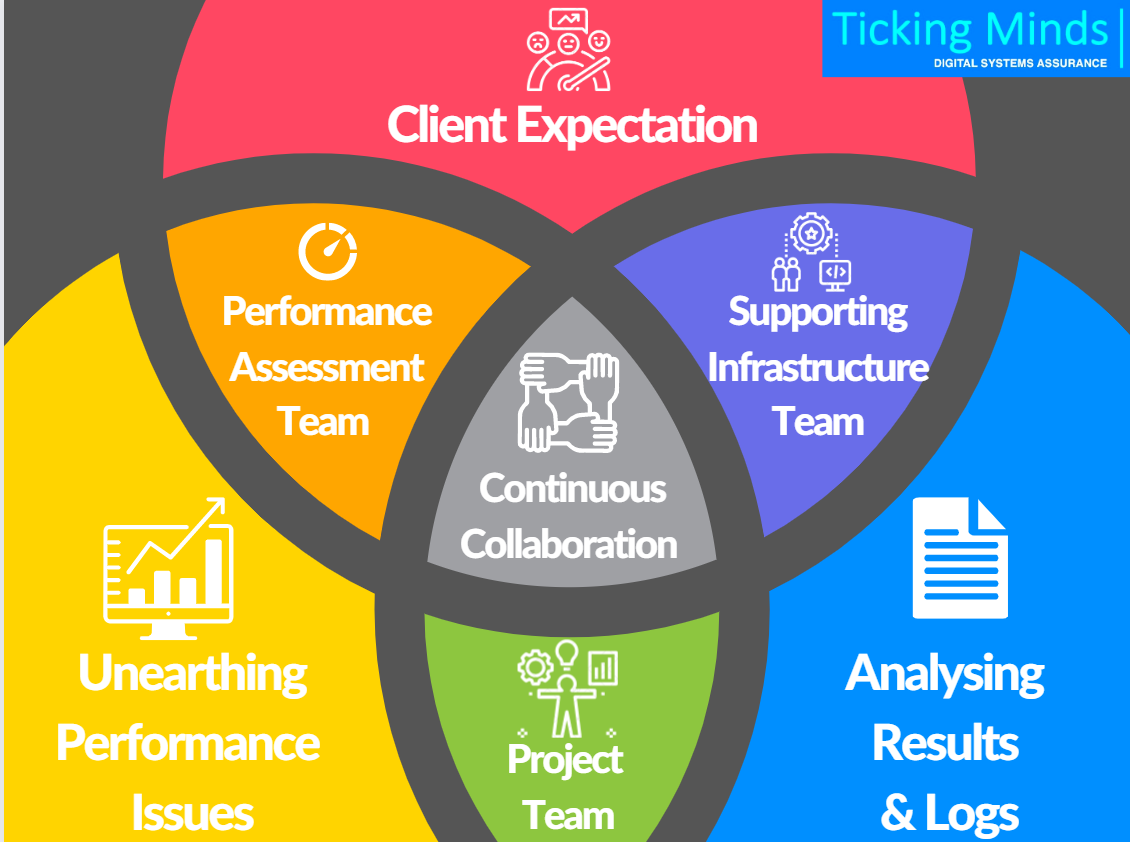
Identifying performance bottlenecks in any application involves three things:
- Carrying out a load / stress / endurance / volume testing
- Monitoring the various parameters/ metrics across client, different server layers
- Analysing the logs /results to understand where the performance bottlenecks are.
It is not an easy task to model a performance test that precisely mimics the production load. Most teams struggle to identify the exact bottleneck while analysing the results and logs.
Based on observation & experience, the number #1 reason for difficulty in performance issues doesn’t pertain only to technical skills, experience, toolsets, or application complexity; but rather, the absence of collaboration between implementation project team, supporting infrastructure/monitoring team, and performance assessment team.
In engagements that require our assistance in performance assessment, it is often the product/performance team that reaches out for help. We try to talk to client facing project/implementation teams to understand their observations on client feedback. Often project teams, business teams, and performance teams work in silos and there is a disconnect from client expectations. Many times, we have run into situations where performance issues are uncovered post-go-lives or just before go-lives. The primary reason that leads to these expensive difficult situations is the lack of continuous collaboration.
Tiny misses in performance tests that can hugely cost enterprises
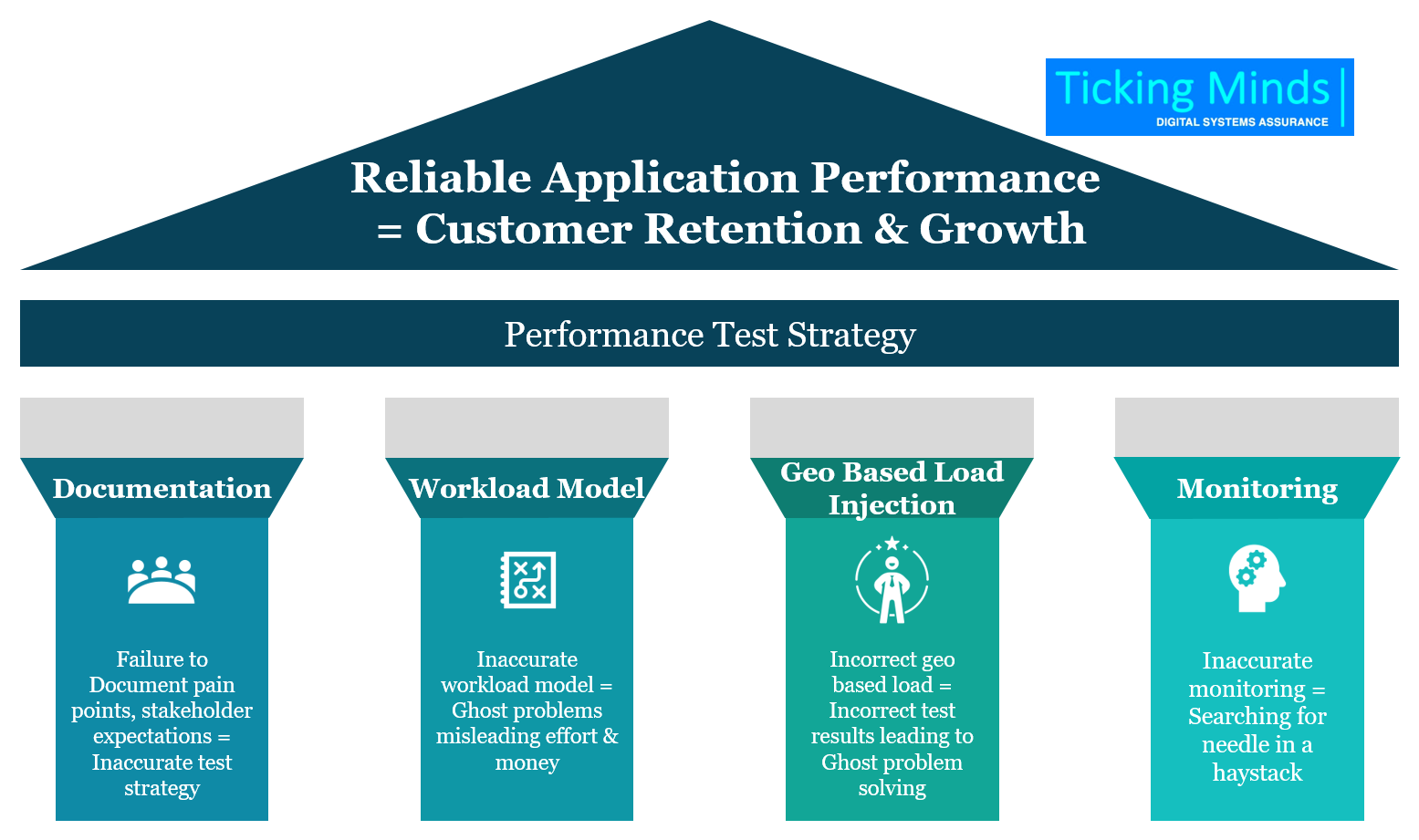
One of the key aspects to performance testing is to understand the expectations of the key stakeholders (business, product owners, technical architects, implementation teams, infrastructure support teams), & document the pain points/issues known. As part of the discussions with various stakeholders, one might derive a lot of historic data related to the usage of the systems, etc. This needs to be documented, and shared with stakeholders as part of receiving the overall sign in. Failure to do so is likely to yield in going-in-circles late in the life cycle.
Workload Model is one of the key components of performance test strategy which essentially captures key operations to be simulated; be it expected number of users in the system for each operation, number of operations that will be performed in a given period of time based on the processing time per request, the think time involved within each step of the particular operation, request arrival rate, duration of the tests; all of which together form a realistic and higher accuracy workload model. Having an inaccurate workload model or not comparatively referring the results with the accurate workload model can skew the performance test results. At times, it might lead the development to chase ghost problems.
Load injection from right location plays a key role in the results. Often when performance tests are carried out, it is important to notice the region from where the intended deployment is to be made and the simulation with load injector happens from the same location. For example, if the intended production is going to be in the US region and the users are also going to come from the same US region, then the load simulation should happen from the US region. If the load simulation happens from another region, say India to the US it is likely to provide inaccurate results due to the additional network hops.
Monitoring in itself is a key element to performance tests. Defining the right layers and right parameters to monitor is important. Often we have seen performance test teams use debug mode logging on server layers, which often leads to disk space exhausted. They might have tended to use for one test for deeper insights but would have forgotten to set it back to minimal debugging. These kinds of ghost issues tend to make infra and technical teams to spend their critical time on ghost problems.
As stated earlier, a functionally rich product coupled with poor performance parameters is dead on arrival. Proper/ accurate performance testing (requirements & performance test data) will ensure that the product/ project is reliable & stable, and enhance customer satisfaction levels; thus increasing customer retention rates and improving Brand Reputation & reliability.

